cn.hutool.extra.ssh.JschRuntimeException: JschException: Session.connect: java.net.SocketException: Connection reset
at cn.hutool.extra.ssh.JschUtil.openSession(JschUtil.java:116)
at cn.hutool.extra.ssh.JschUtil.openSession(JschUtil.java:97)
at cn.hutool.extra.ssh.JschSessionPool.lambda$getSession$64b21fc$1(JschSessionPool.java:45)
at cn.hutool.core.lang.SimpleCache.get(SimpleCache.java:112)
at cn.hutool.extra.ssh.JschUtil.getSession(JschUtil.java:55)
at cn.hutool.extra.ssh.Sftp.init(Sftp.java:166)
at cn.hutool.extra.ssh.Sftp.init(Sftp.java:93)
at cn.hutool.extra.ssh.Sftp.init(Sftp.java:80)
at cn.hutool.extra.ssh.Sftp.init(Sftp.java:70)
at cn.hutool.extra.ssh.Sftp.init(Sftp.java:56)
at
WITH RECURSIVE descendants AS (
-- 初始条件
SELECT id, parent_id, name
FROM my_table
WHERE id = 1
UNION ALL
-- 递归条件
SELECT t.id, t.parent_id, t.name
FROM my_table t
JOIN descendants d ON t.parent_id = d.id
)
SELECT id, name FROM descendants WHERE id <> 1;
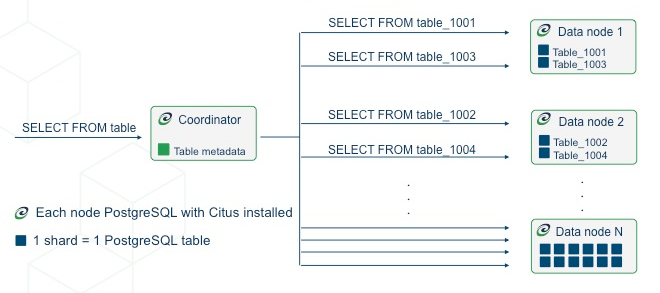
# 预加载citus扩展
sudo pg_conftool 15 main set shared_preload_libraries citus
# 修改监听IP,这里我直接改了 *,如果是暴露在公网的建议只监听内网ip
sudo pg_conftool 15 main set listen_addresses '*'
# 修改添加四台节点互信
sudo vim /etc/postgresql/15/main/pg_hba.conf
#在最底下追加下面内容
host all all 192.168.10.202/24 trust
host all all 192.168.10.101/24 trust
host all all 192.168.10.102/24 trust
host all all 192.168.10.103/24 trust
#重启
systemctl restart postgresql