
Citus官方有一个开源的postgres高可用工具 pg-auto-failover
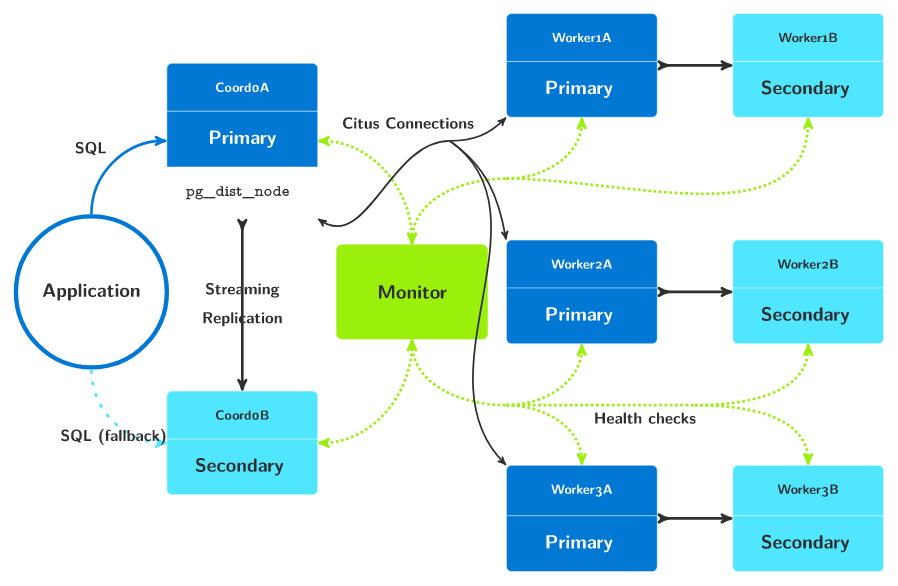
Citus官方有一个开源的postgres高可用工具 pg-auto-failover
HTTPS(超文本传输安全协议)的连接流程结合了传输层的TCP三次握手和TLS(传输层安全性协议)的握手过程来提供一个安全的连接。这个过程可以大致分为以下几个步骤:
这是任何HTTP或HTTPS连接开始的地方。客户端和服务器之间建立一个TCP连接,这是一个可靠的连接,确保了数据包正确无误地到达。
在TCP连接成功建立之后,TLS握手过程开始,目的是安全地交换密钥,验证服务器,并且建立加密通道。
客户端发送一个“Client Hello”消息到服务器,包含:
服务器响应一个“Server Hello”消息,包含:
客户端验证服务器证书的有效性,它可能包括:
客户端使用从服务器证书中提取的公钥,发送预主密钥(Pre-Master Secret),这通常是加密的。
客户端和服务器都使用客户端随机数、服务器随机数和预主密钥生成相同的会话密钥,这将用于此后的对话加密。
客户端发送一个“Finished”消息,这通常是之前所有消息的加密和散列值,用于服务器验证。
服务器同样发送一个“Finished”消息,客户端验证这个消息以确保没有中间人攻击。
HTTPS使用的是一种称为公钥基础设施(PKI)的体系结构,在这种体系结构中,确实使用了公钥和私钥机制,但它结合了对称加密和非对称加密的优点来提供安全通信。
TCP三次握手例子:
假设你的电脑(客户端A)尝试通过TCP连接到一个网站的服务器(服务器B)。服务器的IP地址是192.168.1.1,客户端的IP地址是192.168.1.2,而你想要访问的服务(比如一个网页)是通过标准的HTTP服务端口80提供的。
源地址:192.168.1.2:12345 目的地址:192.168.1.1:80 Seq=1000 ACK=0 Flags=[SYN]源地址:192.168.1.1:80 目的地址:192.168.1.2:12345 Seq=5000 ACK=1001 Flags=[SYN, ACK]源地址:192.168.1.2:12345 目的地址:192.168.1.1:80 Seq=1001 ACK=5001 Flags=[ACK]TCP三次握手作用包括:
三次握手是对建立TCP连接过程的最小化要求,它可以有效地启动一个双向通信会话,同时避免了一些常见的网络通信问题。如果减少到两次握手,那么就无法解决上述的第三个问题,也就是说,如果网络中存在延迟的连接请求,那么这样的请求可能会导致不必要的连接建立,从而造成混乱。三次握手是在效率和可靠性之间的一个妥协。
四次挥手断开TCP连接的例子:
假设客户端A与服务器B之间建立了一个TCP连接,并且在此期间它们已经交换了一些数据。现在,客户端A决定关闭这个连接。以下是关闭过程的详细步骤和假设的序列号及确认号。
源地址:客户端A 目的地址:服务器B Seq=10001 Ack=5001 Flags=[FIN, ACK]源地址:服务器B 目的地址:客户端A Seq=服务器B当前的序列号 Ack=10002 Flags=[ACK]源地址:服务器B 目的地址:客户端A Seq=8001 Ack=10002 Flags=[FIN, ACK]源地址:客户端A 目的地址:服务器B Seq=10002 Ack=8002 Flags=[ACK]TCP的四次挥手(Four-way Handshake)断开连接的过程比建立连接的三次握手(Three-way Handshake)要复杂,这主要是因为TCP连接是全双工的,意味着每个方向的通信是独立的。这里是为什么需要四次挥手的一些原因:
总结来说,四次挥手的过程确保了连接的双方都能够完全完成数据传输,并且优雅地关闭连接,没有任何一方突然中断连接导致数据丢失。这也是为什么不能简化为三次或更少次数的原因,因为TCP设计的优先考虑是确保数据传输的可靠性和完整性。
编译器生成字节码时的优化
编译器在生成字节码时可以进行一些优化,以提高代码的执行效率和性能。以下是一些常见的优化技术:
这些优化技术可以帮助编译器生成更高效的字节码,从而提高代码的执行效率和性能。编译器根据代码的特性和优化策略的选择,可以进行不同程度的优化。
JVM在运行时执行的一些关键优化:
JVM的优化是一个持续的过程,随着程序的运行,JVM会逐渐学习并应用越来越多的优化策略,以期达到最优性能。
Java中的基本数据类型和它们的封装类(有时被称作包装类)之间存在一些关键的不同点,这些设计主要是为了解决基本数据类型在面向对象编程中的局限性。
int, double, char等)通常会有更好的性能,因为它们存储的是值,且存储在栈上。int的默认值为0,boolean的默认值为false,无需显式初始化。Integer, Double, Character等)是类,它们包装了基本类型的值并提供了对象的特性。null,表示这个引用不指向任何对象,而基本数据类型不能赋值为null。List, Set, Map等)只能存储对象,不能存储基本类型。这就是封装类存在的主要原因之一。封装类和基本数据类型之间的转换是自动的,这个特性被称为自动装箱和拆箱。例如,当你把一个int赋值给一个Integer对象时,自动装箱就发生了;反过来,当你把一个Integer赋值给一个int时,就会发生自动拆箱。这种设计让开发者能够在面向对象编程和性能之间找到平衡点。
int默认是0,而不是null时。int[]),这样做可以减少内存消耗并提高处理速度。ArrayList、HashMap时,只能存储对象。null值:如果你需要表示一个变量可能没有值(即null),或者需要在某些业务逻辑中区分0和null。ArrayList<Integer>,必须使用封装类。UTF-8使用一至四个字节为每个字符编码,编码规则如下:
每个字节中,以10开头的字节为后续字节,它们不会独立出现,只会跟随一个高位字节。这种编码方法的一个优势是通过查看任意字节,都能够知道它是单独的字符还是某个字符的一部分,因为UTF-8字节序列是顺序无关的,所以不像UTF-16和UTF-32,UTF-8不需要字节顺序标记(BOM)来指示字节的顺序。
UTF-16(16-bit Unicode Transformation Format)使用单个16位的代码单元来编码U+0000至U+FFFF之间的字符,这部分包括了基本的多语言平面(BMP)。对于更高位的字符,则使用一对16位的代码单元,即32位来编码,这种对称称为代理对(Surrogate Pair)。
安装软件
RyzenAdj 命令行控制AMD APU工具
Ryzen Controller 封装RyzenAdj的GUI工具(简单好用,而且支持中文)
同类型的封装RyzenAdj的GUI工具 还有RyzenAdjCtl它可以做到更加细粒度的控制这类工具主要是针对移动端的AMDAPU,对于桌面端的支持不是太好。
博主使用的是桌面端的5600G,测试时发现RyzenAdj只能控制CPU功耗,设置GPU频率不生效。
针对iGPU,可以使用这个工具Radeon Profile,它是Linux下AMD显卡的专用超频工具,虽然它没法对我们的核显超频,但是可以在首页控制核显运行频率来大幅度减少功耗。
RyzenAdj效果
在默认设置时,随便播放一个1080P视频,功耗在50W上下
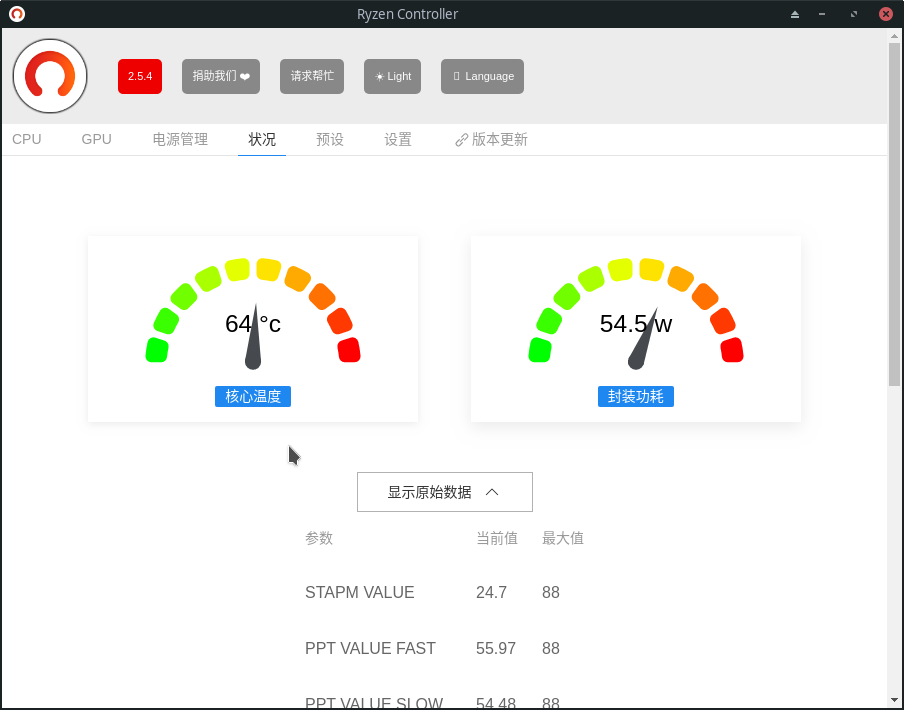
手动设置功耗墙到10W
播放同样的1080P视频,功耗和温度显著降低,这时候打开任务管理器可以发现CPU占用提高很多,但丝毫不影响视频播放的性能。
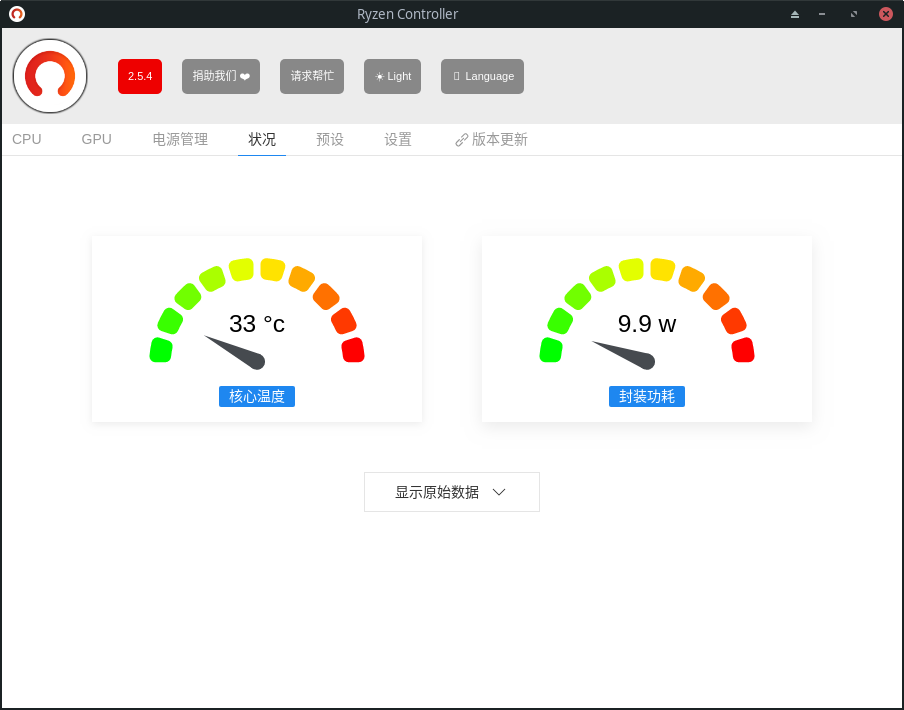
Radeon Profile效果
功耗计实测
在没置功耗墙之前,整机待机功耗73W左右(7块硬盘+pcie网卡+pcie转sata卡+4根16G 3200内存),突然负载时功耗能飙到140W,满载功耗也在130W。设置功耗墙为10W后,整机功耗最多也就84W,这时候性能确实拉了,但是日常使用并用作NAS已经是绰绰有余了,非常满意!
超全的JackSon注解大全包含demo https://www.tutorialspoint.com/jackson_annotations/index.htm
map属性作为标准属性, 在反序列过程中, 从Json字符串得到的属性值会加入到map属性中,可以用它来存不存在于类中的属性。Map类型属性当做标准属性,和@JsonAnySetter一起使用 
注意:虽然官方文档说 该注解如果和@JsonIgnore一同使用,@JsonIgnore 则优先于此属性。但实际测试用发现如果两个注解同时存在,效果等同 READ_ONLY,序列化都能展示,反序化不能写入。
String value: 指定序列化key
String defaultValue: 指定key的默认值
boolean required:是否必须,但请注意,从 2.6 开始,此属性仅用于 Creator 属性,以确保 JSON 中存在属性值:对于其他属性(使用 setter 或可变字段注入的属性),不执行验证,也就是说只和@JsonCreator一起使用时生效。
int index: 指定该字段排序
JsonProperty.Access access: 序列化权限控制 有下列四种
序列化权限控制测试代码:MyTest.java
@NoArgsConstructor
@AllArgsConstructor
@Builder
@Data
public class MyTest {
@JsonProperty(access = AUTO)
public String myA;
@JsonProperty(access = READ_ONLY)
public String myB;
@JsonProperty(access = WRITE_ONLY)
public String myC;
@JsonProperty(access = READ_WRITE)
public String myD;
public static void main(String[] args) throws JsonProcessingException {
MyTest myTest = MyTest.builder().myA("A").myB("B").myC("C").myD("D").build();
ObjectMapper mapper = new ObjectMapper();
String toJson = mapper.writeValueAsString(myTest);
System.out.println("=======预期打印======");
System.out.println("{\"myA\":\"A\",\"myB\":\"B\",\"myC\":\"C\",\"myD\":\"D\"}");
System.out.println("=======序列化打印=====");
System.out.println(toJson);
System.out.println("=======反列化打印=====");
String fromJson = "{\"myA\":\"A\",\"myB\":\"B\",\"myC\":\"C\",\"myD\":\"D\"}";
MyTest test = mapper.readValue(fromJson,MyTest.class);
System.out.println(test);
}
}
输出结果:
=======预期打印======
{"myA":"A","myB":"B","myC":"C","myD":"D"}
MyTest(myA=A, myB=B, myC=C, myD=D)
=======序列化打印=====
{"myA":"A","myB":"B","myD":"D"}
=======反列化打印=====
MyTest(myA=A, myB=null, myC=C, myD=D)
JackSon默认使用无参构造方法和set方法反序列对象,使用该注解可以指定JaskSon使用指定方法进行反序列化构造对象,可以标注在构造方法和静态工厂方法上。
@JsonView使用方法:
1.使用接口来声明多个视图 例如下面这个 代码来自baeldung.com
public class Views {
public static class Public {
}
public static class Internal extends Public {
}
}
public class Item {
@JsonView(Views.Public.class)
public int id;
@JsonView(Views.Public.class)
public String itemName;
@JsonView(Views.Internal.class)
public String ownerName;
}
2.在pojo的属性上指定视图
public class Item {
@JsonView(Views.Public.class)
public int id;
@JsonView(Views.Public.class)
public String itemName;
@JsonView(Views.Internal.class)
public String ownerName;
}
3.在Controller方法上指定视图
@JsonView(Views.Internal.class)
@RequestMapping("/items/internal/{id}")
public Item getItemInternal(@PathVariable int id) {
return ItemManager.getById(id);
}
4.直接进行序列化或反序列化时可以指定视图
@Test
public void whenUseJsonViewToDeserialize_thenCorrect()
throws IOException {
String json = "{"id":1,"name":"John"}";
ObjectMapper mapper = new ObjectMapper();
User user = mapper
.readerWithView(Views.Public.class)
.forType(User.class)
.readValue(json);
assertEquals(1, user.getId());
assertEquals("John", user.getName());
}
@JsonView是jackson json中的一个注解,指定属性后序列化将只使用该属性值作为序列化接口(这个注解只能作用于一个属性上)。
@JsonUnwrapped 对象扁平化 如果属性序列化后是一个对象 会将该属性的对象解构提取到根对象中。
用于绑定被注释类所具有的逻辑名称的注释。与JsonTypeInfo(特别是JsonTypeInfo.use()属性)一起使用以建立对象名称和属性之间的关系,反序列化为父类时,用于确定该对象的具体类型,与@JsonSubTypes 直接标注在父类等效。
用于多态类型处理
Class<?> defaultImpl 指定默认的反序列化类型,当反序列对象无法映射到现在有的指定类型时会使用它进行反序列化。
JsonTypeInfo.As include 指定类型标识信息的展示方式。
有下列5种可选值 下面的测试结果使用的注解是@JsonTypeInfo(use= JsonTypeInfo.Id.NAME)
PROPERTY 使用单个可配置属性的包含机制,与实际数据(POJO 属性)一起作为单独的元属性包含在内。,这个属性的值由 @JsonTypeInfo注解的property确定,否则就使用不同use情况下的默认值(@class、@c、@type)。
@JsonTypeInfo(use= JsonTypeInfo.Id.NAME,
include = JsonTypeInfo.As.PROPERTY )
结果:
=======未配置注解打印======
{"myA":"A","myB":"B","myC":"C","myD":"D"}
=======配置注解打印=======
{"@type":"MyTest","myA":"A","myB":"B","myC":"C","myD":"D"}
EXISTING_PROPERTY 与PROPERTY区别在于,该注解在序列化时不会输出标识符,反序列流程根PROPERTY相同。
EXTERNAL_PROPERTY 只作用于属性上,把子属性的标识符提升到根对象里,具体使用场景没搞明白。
WRAPPER_OBJECT 包裹在一个对象中,相当于在外层创建一个父对象 {标识符:{原本的对象}} 用一个大对象包住
@JsonTypeInfo(use= JsonTypeInfo.Id.NAME,
include = JsonTypeInfo.As.EXTERNAL_PROPERTY )
结果:
=======未配置注解打印======
{"myA":"A","myB":"B","myC":"C","myD":"D"}
=======配置注解打印=======
{"MyTest":{"myA":"A","myB":"B","myC":"C","myD":"D"}}
WRAPPER_ARRAY 包裹在一个数组中。
@JsonTypeInfo(use= JsonTypeInfo.Id.NAME,
include = JsonTypeInfo.As.WRAPPER_ARRAY )
结果:
=======未配置注解打印======
{"myA":"A","myB":"B","myC":"C","myD":"D"}
=======配置注解打印=======
["MyTest",{"myA":"A","myB":"B","myC":"C","myD":"D"}]
JsonTypeInfo.Id use 指定在序列化时类型标识信息展示的值。
有下列5种可选值
CLASS 意味着使用完全限定的 Java 类名作为类型标识符。
测试结果:可以看到序列化对象多了一个 @class key,而且其值为全限定类名。(若不指定property则默认为@class)
=======未配置注解打印======
{"myA":"A","myB":"B","myC":"C","myD":"D"}
=======配置注解打印========{"@class":"com.example.demo.bean.MyTest","myA":"A","myB":B,"myC":"C","myD":"D"}
CUSTOM 意味着键入机制使用自定义处理,可能具有自定义配置。这个注解需结合property属性和@JsonTypeIdResolver一起使用,指定类标识符的值。
@JsonTypeInfo(use = JsonTypeInfo.Id.CUSTOM, property = "type") @JsonTypeIdResolver(JacksonTypeIdResolver.class) 实现TypeIdResolver接口 自定义序列化流程
MINIMAL_CLASS 表示使用具有最小路径的 Java 类名作为类型标识符,多了一个”@c“字段,其值为最小路径类名。(若不指定property则默认为@c)
=======未配置注解打印======
{"myA":"A","myB":"B","myC":"C","myD":"D"}
=======配置注解打印=======
{"@c":".MyTest","myA":"A","myB":"B","myC":"C","myD":"D"}
NAME 表示使用逻辑类型名作为类型信息;然后需要将名称单独解析为实际的具体类型(类),多了一个”@type”字段,其值为类名。(若不指定property则默认为@type)
=======未配置注解打印======
{"myA":"A","myB":"B","myC":"C","myD":"D"}
=======配置注解打印=======
{"@type":"MyTest","myA":"A","myB":"B","myC":"C","myD":"D"}
NONE 这意味着不包含显式类型元数据,并且键入纯粹是使用上下文信息完成的,可能会增加其他注释。
=======未配置注解打印======
{"myA":"A","myB":"B","myC":"C","myD":"D"}
=======配置注解打印=======
{"myA":"A","myB":"B","myC":"C","myD":"D"}
String property 指定类标识名称,在include=JsonTypeInfo.As.PROPERTY或use=JsonTypeInfo.Id.CUSTOM生效,其他情况使用默认的识别码名称。
注意:include=JsonTypeInfo.As.PROPERTY和property同时存在有个问题,如果POJO具有相同名称的属性,会出现两个!
@JsonSubTypes
用来列出给定类的子类,只有当子类类型无法被检测到时才会使用它,也可以在子类上直接使用@JsonTypeName 实现同等效果。
博主最近不小心买了很多吃灰服务器,正好可以拿去Java微服务相关,基于选新不选旧原则,直接开始学习SpringCloud。学习的过程中,遇到过两次sentinel面板数据空白的问题,先说解决方案
1.部署sentinel服务器和部署微服务服务器必须要开放对应端口!!sentinel的实时监控是通过调用机器Adapter获取实时监控的。
2.时间和时区要一致!!!(博主的吃灰服务器主要是欧洲和美国的,但是部署的时候发现,sentinel只有微服务启动的时候才会显示实时监控,一段时间后就不显示了,这就是时间和时区不一致导致的)